Attention and Transformer
约 2596 个字 307 行代码 4 张图片 预计阅读时间 21 分钟
Attention 让模型在生成或编码每个 token 时动态选择相关上下文,解决传统 Seq2Seq 固定上下文向量的信息瓶颈.本节从 Bahdanau Attention 过渡到 Self-Attention 和 Transformer.
推荐材料:Coding a Transformer from scratch on PyTorch
跟随视频的完整代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 | |
1. Bottleneck in Seq2Seq
在语言建模中提到的 Seq2Seq 模型,有两个问题:
- 信息压缩:源句越长,越难把所有信息都压进一个固定长度向量里;这个问题在 LSTM、GRU 中仍然存在.
- 缺少动态性:翻译一句话时,生成不同目标词通常需要关注源句中的不同部分;而传统 seq2seq 中上下文向量是固定的.
按照人类的行为,如果我们来做翻译,会动态地根据前文来判断当前词语的含义.这就引出了注意力的概念.
2. Bahdanau Attention
由于需要动态查看前文,因此不再是看一个固定的上下文向量,而是把所有的隐状态都保留下来.
解码器生成第 \(t\) 个词时,模型会重新查看所有的隐状态,并将隐状态加权求和得到一个特定的上下文向量,这个向量包含了生成这个词需要特别关注的内容.
具体过程:
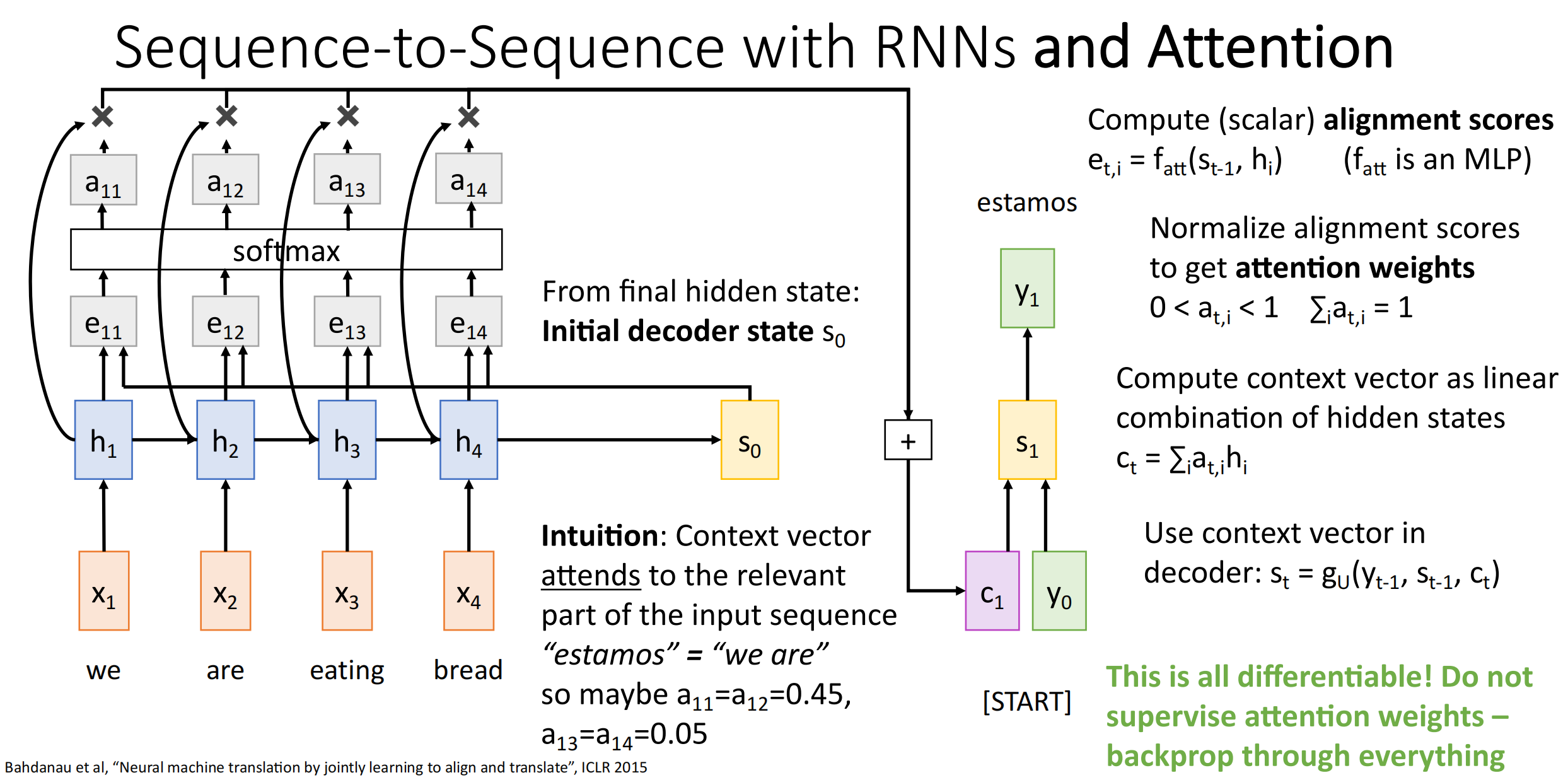
- 解码器当前状态 \(s_{t-1}\) 和所有隐状态 \(h_i\) 计算得到分数 \(e_{i,t}\).其使用的是一个小型前馈神经网络.
- 得到了分数后,用 softmax 函数对其进行归一化处理得到注意力权重 \(\alpha_{i,t}\).
- 再用注意力权重对隐状态进行加权求和,即 \(c_t=\sum\alpha_{t,i}h_i\),得到此时的上下文向量.
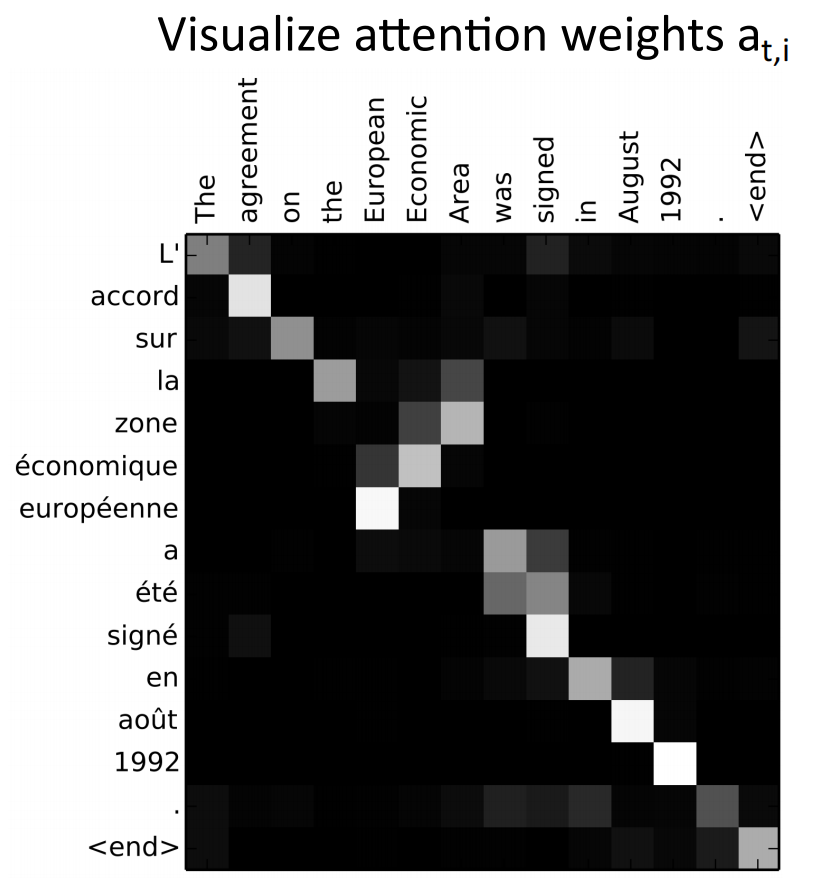
可视化
我们用机器翻译的结果,对注意力权重进行可视化:可以发现对应的词语的注意力权重会较高,如英语中的 Area 对应法语中的 zone、European 对应 européenne 等.
3. Cross-Attention
为了方便计算,我们直接取上文中计算分数的方式为向量点积.这样我们还能用矩阵来进行并行计算.这样就引出了接近现代注意力机制的 Cross-Attention(交叉注意力).
3.1 Query、Key、Value
现代 Attention 通常用 Query、Key、Value 来描述检索过程:
- Query 表示需求;
- Key 用来参与匹配;
- Value 用来提供内容.
与 Bahdanau Attention(用隐状态同时来匹配与输出内容)最大的差别是把 Key 和 Value 分开了.这样的好处是用于匹配的信息和最终取回的信息可以不一致.
例如使用 Google 搜索“世界上最高的山是什么”,参与匹配的 key 是”世界上最高的山”这个问题本身,而“珠穆朗玛峰”才是需要的 value.
3.2 Matrices Form
假设查询序列 \(X\in \mathbb{R}^{N_x\times d}\),被查询序列 \(Y \in \mathbb{R}^{N_y\times d}\).其中 \(N_q、N_y\) 为查询序列的长度,\(d\) 为每个 token 的维度.
投影矩阵 \(W_Q\in \mathbb{R}^{d\times d_k}\),\(W_K\in \mathbb{R}^{d\times d_k}\),\(W_V=\in \mathbb{R}^{d\times d_v}\)(一般取 \(d_v=d_k\)).
首先将查询矩阵与被查询矩阵投影得到 \(Q、K、V\):
- \(Q=XW_Q\in \mathbb{R}^{N_x\times d_k}\)
- \(K=YW_K\in \mathbb{R}^{N_y\times d_k}\)
- \(V=YW_V\in \mathbb{R}^{N_y\times d_v}\)
然后计算 query 和 key 的相似度矩阵 \(S=QK^T\in \mathbb{R}^{N_x\times N_y}\),其表示查询序列对被查询序列的相关性分数.
如果直接做点积运算,\(S\) 中的每一个元素都是 \(d_k\) 对乘积的和.当 \(d_k\) 很大时,点积数值也会变大,导致 softmax 结果十分尖锐(某一位置概率接近 1,其他都接近 0),导致梯度变小等问题.具体而言,如果 \(Q、K\) 元素服从标准正态分布,那么 \(d_k\) 项乘积和方差接近 \(d_k\),因此需要除以标准差 \(\sqrt{d_k}\) 来实现方差归一化.
得到相关性分数后,再用 softmax 对分数进行归一化.接着对 value 进行加权平均,得到的维度为 $ \mathbb{R}^{N_x\times d_v}$,即每一个查询都有对应的注意力分布.
即完整公式为:
注意力机制最后得到的输出是什么?
其输出维度和输入是完全一致的,每一个 token 的词向量表示都是 \(V\) 中词向量的加权组合,可以理解为融合了其他词向量.
4. Self-Attention
对于一个序列里的 token,其如果想了解上下文并关注自己与其他 token 的相关性,就需要这个序列对自己做一次交叉注意力,即 Self-Attention(自注意力).
自注意力与交叉注意力在形式上的区别就是查询矩阵和被查询矩阵都是 \(X\).
在自注意力中,任意两个 token 可以直接进行交互,信息路径更短,容易建立长距离依赖;并且其主要计算均为矩阵乘法,天生容易并行;因此其天生适合序列建模.
但自注意力机制仍然有许多不足,而这些不足将在后续内容中提出解决方案.
5. Positional Encoding
自注意力的问题之一:它不知道 token 之间的顺序,因此不知道顺序带来的影响.
考虑两个 3 token 序列:dog bites man 和 man bites dog.这两个句子包含的词完全一样,但顺序不同,意思也完全不同.而对自注意力来说,两个输入 token 交换了顺序,但它们都是做相同的矩阵乘法,最后的结果也只是输出调换了位置.
最直接的解决方法是给每个位置加上一个 embedding 向量,即 \(z_i=x_i+p_i\),或矩阵形式 \(Z=X+P\).而使用相加而非拼接,好处是不会改变向量维度,可以直接套用原来的模型.
正弦位置编码
在原始 Transformer 论文中,作者采用了固定的正弦位置编码,直接由公式生成;对于位置 \(pos\) 和维度 \(i\),其定义为:
当然,也可以使用可学习的位置编码.
6. Multi-Head Attention
如同 CNN 需要多个卷积核提取多个特征一样,注意力也需要有一种能让一组 token 建立不同联系的方法,如语法、语义.因此 Transformer 论文中提出了 Multi-head Attention(多头注意力).
对于常见的 \(d_k=d_\text{model}=512、h=8\),其做法是 \(W_Q,W_K,W_Q\) 用 \(512 \to 512\) 的线性层让同一个 token 的表示充分融合,然后直接将这 \(512\) 拆分成 \(8\times 64\)(此时 64 即为 \(d_k\)) ,再将 \(h\) 维度与 \(seq\_len\) 维度置换,从而方便使用矩阵进行并行计算.也就是说多个头,其实是在一个张量内部完成的.计算时 \(h\) 是张量的第一维.
最后每一个头得到最后一维是 64 的输出,将它们拼起来再置换,恢复成输入形状.
在 Transformer 中,Cross-Attention 与 Self-Attention 使用的均为 Multi-Head Attention,只是传入作为 Q、K、V 的张量不同.
7. Layer Norm
处理文本时,由于不同序列文本长度不一致,因此 BatchNorm 在批之间归一化的方式并不好用;常使用 Layer Normalization(层归一化).
Layer Norm 是把每个 token 的向量表示进行归一化.即对于 (batch, seq_len, d_model) 的输入,其在 d_model 维度进行归一化.归一化步骤同 BatchNorm:减去均值、除以标准差,再乘以可学习的缩放、加上可学习的偏置(一般维度为 d_model).
8. Transformer
至此,Transformer 架构的基本单元已经集齐.Transformer 架构图:
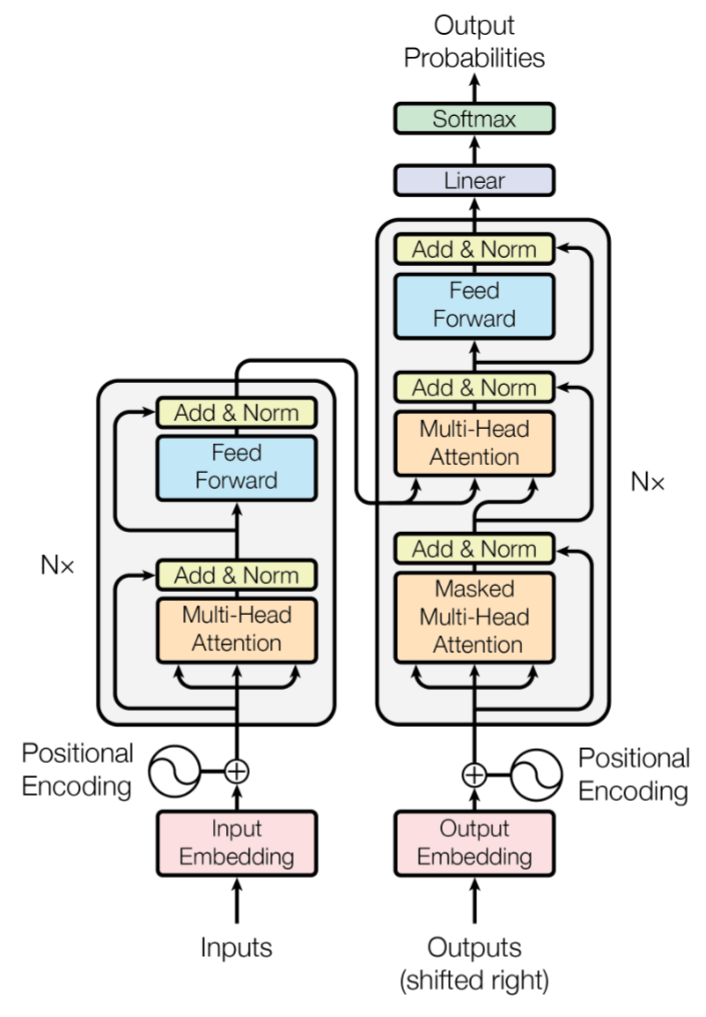
8.1 Encoder Block
根据架构图,输入经过词嵌入后加上位置编码进入 Encoder Block.每个 Encoder Block 包含 Multi-Head Self-Attention 和 Feed-Forward Network 两个模块,每个模块都各自包含 LayerNorm、Dropout 和 Residual Connection.
所以,一个 Encoder Block 可以写成:
8.1.1 Pre-Norm 与 Post-Norm
原始 Transformer 中将 LayerNorm 放在子模块和残差连接之后,这种称为 Post-Norm.现代 Transformer 实现中,更常见的是 Pre-Norm,将 LayerNorm 放在子模块和残差连接之前:
具体原因可以参考苏剑林老师的博客:为什么Pre Norm的效果不如Post Norm?
8.2 Decoder Block
Decoder Block 由三个类似模块组成,分别包含 Masked Self Attention、 Cross Attention、Feed Forward Netword,和对应的 Norm 与 Residual.
8.2.1 Masked Self Attention
在训练 Decoder 时,通常会把目标序列右移一位作为输入:
1 2 | |
训练时采用 Teacher Forcing 方法:训练时的历史 token 来自真实答案而不是模型自己生成的结果.同时一次性输入完整前缀能发挥 Attention 的并行优势.
但是一次性输入完整前缀,模型会偷看未来,因此要加上 Causual Mask,保证自注意力只能注意到自己及之前,即:
1 2 3 4 | |
从实现角度,在自注意力计算得到分数后、进入 softmax 之前,将自注意力矩阵不含对角线的右上三角全部设为 \(-\infty\);保证 softmax 后的结果和为 1 的同时防止模型偷看未来.
推理时,模型没有正确答案,每一次生成下一 token 后再进行下一次自注意力串行推理,即自回归生成.
8.2.2 Cross Attention
Encoder 侧处理输入序列后得到源序列的上下文表示 \(H_\text{enc}=\text{Encoder}(X)\);将 \(H_\text{enc}\) 作为 K、V,Decoder 侧输入经过 Masked Self-Attention 后得到的上下文表示作为 Q,进行 Cross-Attention.
8.3 Transformer
根据架构图,将 Encoder / Decoder Block 堆叠 N(一般取 6)次后得到 Encoder / Decoder,再与开始的词嵌入层、位置编码,最后的线性投影层、输出层连接得到完整的 Transformer.