Language Modeling
约 1036 个字 2 张图片 预计阅读时间 5 分钟
1. Task
语言模型最核心的目标是学习语言序列的概率分布,即得到
\[
P(x_1,x_2,\dots,x_T)
\]
或者将联合概率拆成条件概率乘积,也就是自回归语言模型的基本思想:
\[
P(X)=\prod_{t=1}^TP(x_t|x_1,\dots, x_{t-1})
\]
语言模型常见用途:
- Score sequences
- Classify text
- Generate sequences(& Conditional generation:如机器翻译)
2. Evaluation
对模型生成结果进行评估的方法:
- Log-likelihood:训练数据的对数似然越大越好
\[
LL(X_{\mathrm{test}})=\sum_{X \in X_{\mathrm{test}}}\log P(X)
\]
长度不同,则需要对 token 求平均:Per-word Log likelihood
\[
WLL(X_{\mathrm{test}})
=
\frac{1}{\sum_{X \in X_{\mathrm{test}}}|X|}
\sum_{X \in X_{\mathrm{test}}}\log P(X)
\]
- Perplexity:困惑度,越低越好.
\[
PPL(X_{\mathrm{test}})
=
e^{-WLL(X_{\mathrm{test}})}
\]
3. Statistical LM
3.1 Bigram Models
Bigram model 根据马尔科夫思想,只使用前一个 token 作为上下文:
\[
P(X)\approx \prod_{t=1}^T p_{\theta}(x_t| x_{t-1})
\]
转化为对数:
\[
\log P(X)\approx \sum_{t=1}^{T}\log p_{\theta}(x_t|x_{t-1})
\]
在训练集中进行计数,得到概率:
\[
p(x_t| x_{t-1})=\frac{\text{count}(x_{t-1},x_t)}{\sum_{x'}\text{count}(x_{t-1},x')}
\]
生成时,根据当前字符,用 multinomial(按概率随机抽样)生成下一个 token.
3.2 N-gram Models
类似 bigram,只是上下文变成 \(n - 1\) 个 token.
N-gram 的问题是:\(n\) 大了以后,很多上下文在训练集根本没出现过,出现数据稀疏情况,导致概率为 0.
于是引入 smoothing(概率总和还是 1,于是分母加上 \(|V|\)):
\[
p(x_t \mid c)
=
\frac{1+\operatorname{count}(c,x_t)}
{|V|+\sum_{x'}\operatorname{count}(c,x')}
\]
N-gram 的问题还有:无法理解语义相似性、上下文窗口短.这些问题推动 nlp 进入下一阶段.
4. Neural Network LM
神经网络语言模型引入神经网络架构来估计单词分布,并通过词向量距离衡量 token 相似度.因此,对于未登录单词,也能通过相似词进行估计,避免数据稀疏问题.
神经网络语言模型一般分为三层:
- 将前 \(n-1\) 个 token 的 one-hot 编码作为原始单词输入,接着通过 embedding 得到词向量,将词向量作为输入 \(x\);
- 通过神经网络架构处理输入 \(x\);
- 最后将处理后的数据投影到 \(|V|\) 维(字典大小)向量,通过概率分布预测下一个 token.
4.1 RNN Language Models
基于 RNN 的序列建模可以实现长距离依赖.在 RNN 语言模型中,模型读入一个 token 后更新 hidden state,再根据当前 hidden state 预测下一个 token.
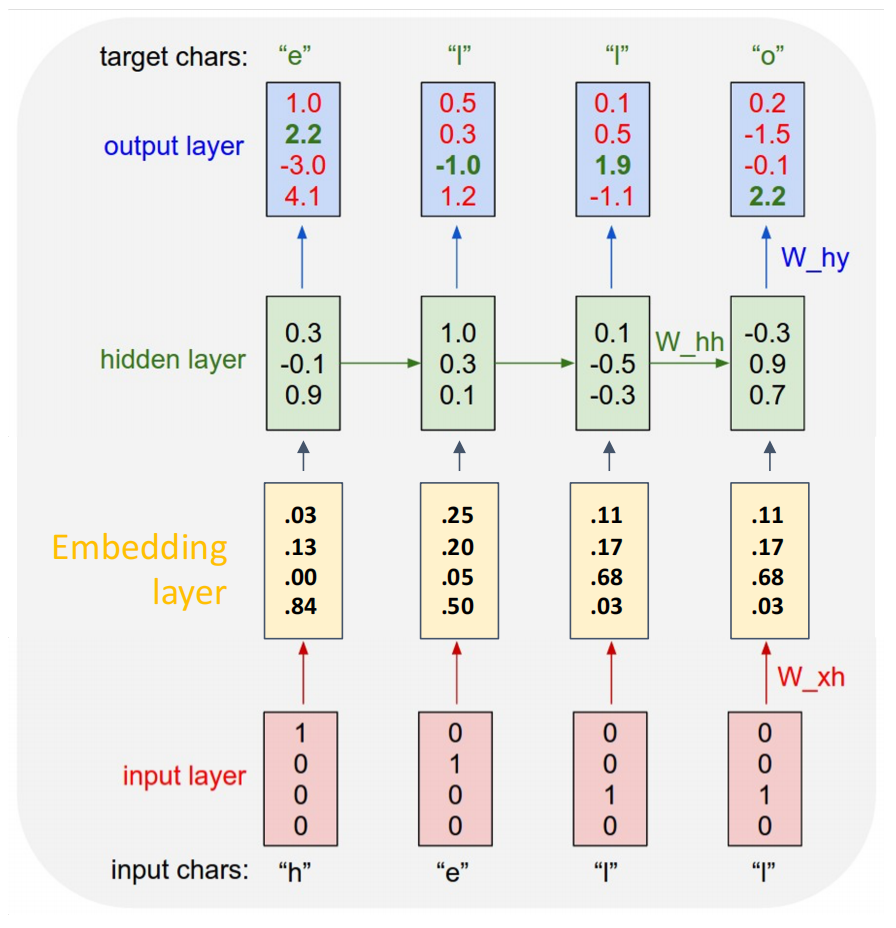
RNN 语言模型训练时和测试时采用不同的方式
- 训练时:每一个输入对应一个输出,一般而言输入序列为
<BOS>+ 原序列,输出序列为 原序列 +<EOS>,偏移一位;同时训练时即使输出错误,也只用于计算 loss 而不会用错误的输出继续往下计算;这种训练方式称为 Teacher Forcing.- 测试时:测试时不会提前给出正确的输出序列,如果一次输出错误,它就会接着这个错误的输出继续生成.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
4.2 Transformer Language Models
基于 Attention 的 Encoder-Decoder 会进一步缓解固定上下文变量的信息瓶颈,具体见 Transformer.