Random Variables
约 1165 个字 13 行代码 4 张图片 预计阅读时间 4 分钟
1. 随机变量
随机变量是一种以概率方式取值的变量.一般用大写字母 \(X,Y,Z\) 来表示随机变量,而用 \(E,F,G\) 来表示事件.
当随机变量被赋予或限定了特定的范围,其成为了事件.如 \(X=2\),\(Y<5\) 等.
2. 离散随机变量
若一个随机变量有有限个可能取值,我们称其为离散随机变量.
2.1 概率密度函数
概率质量函数(Probability Mass Funtion)是离散随机变量在各特定取值上的概率函数.
我们通常用 \(\text{P}(X=x)\) 来表示随机变量 \(X\) 的PMF,有时也会简写为 \(\text{P}(x)\).
例
对于随机变量 \(X\):掷一次骰子的点数,其PMF为
显然对于PMF,有 \(\sum_{x}P(X=x)=1\),其中 \(x\) 为随机变量 \(X\) 的所有可能取值.
2.2 期望
随机变量 \(X\) 所有可能取到的值与该值对应出现概率的加权平均称为随机变量 \(X\) 的期望,记作 \(\text{E}[X]\).
期望具有如下性质:
- 线性性:\(\text{E}[aX+b]=a\text{E}[X]+b\),\(\text{E}[X+Y]=\text{E}[X]+\text{E}[Y]\).(不管 \(X,Y\) 具有何种关系)
- 无意识统计学家法则(LOTUS):\(\text{E}[g(X)]=\sum_xg(x)\text{P}(X=x)\).
2.3 方差
方差是用来衡量随机变量离散程度的指标.对于期望为 \(\text{E}[X]=\mu\) 的随机变量 \(X\),其方差定义为
该计算可以被简化:
方差具有以下性质:
- 线性变换的方差:\(\text{Var}(aX+b)=a^{2}\text{Var}(X)\).
- 若 \(X,Y\) 为独立随机变量:\(\text{Var}(X+Y)=\text{Var}(X)+\text{Var}(Y)\).
2.4 标准差
方差的单位是原单位的平方,为了让单位变回原来的单位,我们将方差开根号得到标准差:\(\text{Std}(X)=\sqrt{\text{Var}(X)}\).
3. 典型离散随机变量分布
3.1 伯努利随机变量
伯努利随机变量是一个布尔变量,其取值只有 \(1\) 或 \(0\),概率分别为 \(p\) 与 \(1-p\).如果 \(X\) 服从伯努利分布,则记作 \(X\sim \text{Ber}(p)\).
离散PMF:
连续PMF:\(\text{P}(X=x)=p^{x}(1-p)^{1-x}\).
期望:\(\text{E}[X]=p\).
方差:\(\text{Var}(X)=p(1-p).\)
伯努利分布期望与方差证明
期望:
方差:
3.2 二项分布
在 \(n\) 次独立重复试验中,每次试验都有 \(p\) 的概率成功,则这一系列试验称为 \(n\) 重伯努利试验.设 \(X\) 为 \(n\) 次实验中的成功次数,则 \(X\) 服从二项分布,记作 \(X\sim \text{Bin}(n,p)\).
PMF:
期望:\(\text{E}[X]=n\cdot p\).
方差:\(\text{Var}(X)=n\cdot p(1-p)\).
二项分布的应用
一场七局四胜的比赛,必须比完七场,我方球队每局胜率为 \(p=0.55\),则总胜率为?
显然答案为
我们用Python得到答案:
from scipy import stats
def binomial():
n = 7
p = 0.55
win = sum(stats.binom.pmf(i, n, p) for i in range(4, n + 1))
return win # 0.608287796875
如果出现某一方球队打赢了四场,那么直接判该球队获胜而不进行后续比赛,此时我方胜率又为多少?
此时仍然为上述答案.因为当一方球队赢下四场后,后续单场比赛结果都不影响最终的结果,我们可以将后面的比赛当作是全概率公式的事件划分,其事件总和为样本空间而每一个情况的最终结果都是同一支队伍获胜,因此后续比赛的概率累计和为 \(1\) 且贡献给同一支队伍,不影响结果.
实际上,如果我们使用负二项分布计算,即准确在第 \(k\) 场赢下第四场,则胜率为
def negative_binomial():
n = 7
p = 0.55
# nbinom.pmf(k, n, p) 中,k 为失败次数,n 为需要达到的成功次数
win = sum(stats.nbinom.pmf(i - 4, 4, p) for i in range(4, n + 1))
return win # 0.608287796875
这与我们使用二项分布计算的结果一致.
二项分布期望与方差证明
不妨设 \(Y\) 为成功概率为 \(p\) 的伯努利变量,\(Y_{i}\) 表示第 \(i\) 次试验是否成功,即 \(Y_{i}\sim \text{Ber}(p)\).
期望:
方差:由于各次试验相互独立
3.3 泊松分布
若事件以已知的恒定平均速率(在给定的一段时间内发生 \(\lambda\) 次)发生,且与上一次事件发生的时间无关,那么描述固定时间内发生特定数量事件的概率的变量 \(X\) 称作泊松随机变量,其服从泊松分布,记作 \(X\sim\text{Poi}(\lambda)\).
PMF:
期望:\(\text{E}[X]=\lambda\).
方差:\(\text{Var}(X)=\lambda\).
泊松分布PMF、期望、方差证明
事件在给定时间 \(t\) 内平均发生 \(\lambda\) 次,将给定时间等分称 \(n\) 份,每一份的时间为 \(t/n\),并假定每一份时间内事件最多发生一次.
我们可以将其近似为二项分布,由于要保证平均发生次数一样,即这 \(n\) 次的二项分布的期望要为 \(\lambda\),因此每一次的发生概率为 \(\lambda/n\).
当 \(n\to \infty\)时,即为泊松分布的PMF:
由于
则
期望:将泊松分布视为二项分布的情况
同理可以得到方差:
3.3.1 泊松分布近似二项分布
由于泊松分布计算公式简洁,当因此当二项分布 \(n\) 较大(>20)而 \(p\) 较小(<0.05)时,我们可以用泊松分布来近似二项分布.
若 \(p\) 稍微大一些,如 \(p=0.5\),对于二项分布而言期望为 \(0.5p\) 而方差为 \(0.25p\),而泊松分布只能模拟期望与方差相差不大的分布.当 \(p\) 较大时,我们考虑使用正态分布近似.
3.4 几何分布
对于有 \(p\) 的概率成功的试验,不断进行直到该试验成功,设 \(X\) 为到成功时的试验次数,则 \(X\) 服从几何分布,记作 \(X\sim \text{Geo}(p)\).
PMF:\(P(X=x)=(1-p)^{1-x}\cdot p,x=1,2,\cdots\).
期望:\(\text{E}[X]=\dfrac{1}{p}\).
方差:\(\text{Var}(X)=\dfrac{1-p}{p^{2}}\).
3.5 负二项分布
对于有 \(p\) 的概率成功的试验,不断进行直到该试验成功 \(r\) 次,设 \(X\) 为到成功 \(r\) 时的试验次数,则 \(X\) 服从负二项分布,记作 \(X\sim \text{NegBin}(r,p)\).
PMF:\(P(X=x)=\dbinom{x-1}{r-1}p^{r}(1-p)^{x-r},x=r,r+1,\cdots\).
期望:\(\text{E}[X]=\dfrac{r}{p}\).
方差:\(\text{Var}(X)=\dfrac{r(1-p)}{p^{2}}\).
3.6 超几何分布
从包含 \(K\) 个成功个体的总体 \(N\) 中,不放回地抽取大小为 \(n\) 的样本.设 \(X\) 为 \(n\) 个样本中成功个体的数量,则 \(X\) 服从超几何分布,记作 \(X\sim \text{HyperGeom}(N,K,n)\).
PMF:\(P(X=x)=\dfrac{\dbinom{K}{x}\cdot\dbinom{N-K}{n-x}}{\dbinom{N}{n}},x=N-K+n,\cdots,K\).
期望:\(\text{E}[X]=n\cdot\dfrac{K}{N}\).
方差:\(\text{Var}(X)=n\cdot\dfrac{K}{N}(1-\cfrac{K}{N})\dfrac{N-n}{N-1}\).
若超几何分布的抽取数量 \(n\) 远小于成功个体数 \(K\) 与失败个体数 \(N-K\),那么抽取对后续概率改变可忽略不计,即近似视为二项分布 \(\text{Bin}(n, \dfrac{K}{N})\).
4. 连续随机变量
4.1 概率密度函数
对于随机变量 \(X\),若存在一个函数 \(f(x)\),满足
则称 \(X\) 为连续随机变量,\(f(x)\) 为 \(X\) 的概率密度函数(Probability Density Function).
\(f(x)\) 可以理解为概率对自变量的导数.易证 \(\text{P}(X=a)=0\),即连续随机变量取任一定值的概率为 \(0\).实际上,PDF的单点数值没有意义,只有积分结果才与概率相挂钩.
由于使用PDF计算概率时每次都要积分,因此我们引入一个累积分布函数(Cumulative Distribution Function)\(F(x)\),定义为 \(f(x)\) 的变上限积分函数:
则 \(\text{P}(a\leq X\leq b)=F(b)-F(a)\).
而对于离散随机变量的CDF可看作是一个前缀和数组.
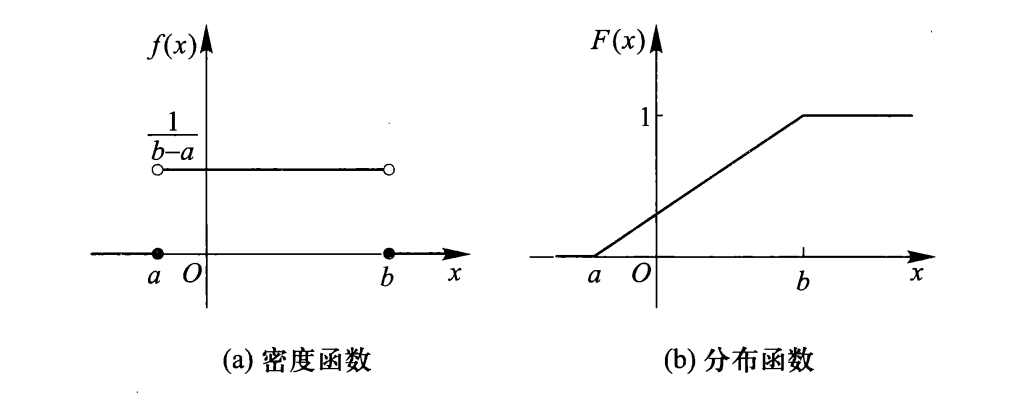
4.2 均匀分布
若连续随机变量 \(X\) 在取值范围 \((a,b)\) 内等可能的取任何值,则称 \(X\) 服从均匀分布,记作 \(X\sim \text{Uni}(a,b)\).
PDF:
CDF:
期望:\(\text{E}[X]=\dfrac{a+b}{2}\).
方差:\(\text{Var}(X)=\dfrac{(b-a)^{2}}{12}\).
4.3 指数分布
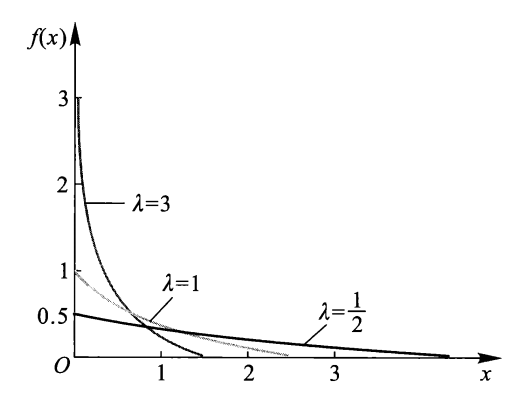
如果一个事件是按照泊松分布发生的,用连续随机变量 \(X\) 衡量直到下一个事件发生所需的时间,则称 \(X\) 服从指数分布,记作 \(X\sim\text{Exp}(\lambda)\),其中 \(\lambda>0\),是泊松分布中的同一参数.
PDF:
CDF:
同时有:\(\text{P}(X>x)=\min (e^{-\lambda x},1)\).
期望:\(\text{E}[X]=\dfrac{1}{\lambda}\).
方差:\(\text{Var}(X)=\dfrac{1}{\lambda^{2}}\).
重要性质——无记忆性:
若 \(X\sim\text{Exp}(\lambda)\),\(\forall t>0,t_{0}>0\),有
也就是说,在等待 \(t_{0}\) 时间后,再等待 \(t\) 时间等到的概率其实和一开始直接等待 \(t\) 时间的概率相等;即从大于 \(0\) 的任意时间开始等相同的时间,等到的概率都是相等的.
4.4 正态分布
正态分布(或称高斯分布)是一个非常常见的连续概率分布,其在自然界中经常出现.实际上世界上许多事物并非正态分布,但科学家仍常常用正态分布来近似建模.因为如果我们只知道一个随机变量的均值和方差,那么正态分布是在满足这两个条件下熵最大的分布,即信息最少、最不带额外主观假设、最保守的一种建模选择.
设连续随机变量 \(X\) 服从正态分布,记作 \(X\sim N(\mu,\sigma^{2})\),其中 \(\mu\) 为期望,\(\sigma^{2}\) 为方差,简称 \(X\) 为正态变量.
PDF:
正态分布的PDF关于 \(x=\mu\) 对称,并在 \(x=\mu\) 处取得最大值 \(\dfrac{1}{\sqrt{2\pi}\sigma}\).
期望:\(\text{E}[X]=\mu\).
方差:\(\text{Var}(X)=\sigma^{2}\).
如果正态变量 \(Y=aX+b\),由于 \(\text{E}[Y]=a\text{E}[X]+b=a\mu +b\),\(\text{Var}(Y)=a^{2}\text{Var}(X)=a^{2}\sigma^{2}\),则 \(Y\sim N(a\mu +b,a^{2}\sigma^{2})\).
4.4.1 标准正态分布
由于正态分布的PDF积分结果无法用初等函数表示,因此我们希望能有一个标准的正态分布,使得其他所有正态分布都能转化为标准正态分布,此时我们只需要研究标准正态分布即可.
记正态变量为 \(Z\),则称 \(Z\sim N(0,1)\) 为 \(Z\) 服从标准正态分布.
- PDF:\(\varphi (x) = \dfrac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}},x\in (-\infty,+\infty)\)
- CDF:\(\Phi(x) = \displaystyle\int_{- \infty}^x \dfrac{1}{\sqrt{2\pi}}e^{-\frac{t^2}{2}} \text{d} t\)
4.4.2 转化为标准正态分布
对于任意正态分布 \(X\sim N(\mu,\sigma^{2})\),令正态变量 \(Z=\dfrac{X-\mu}{\sigma}\),则 \(Z\sim N(\dfrac{1}{\sigma}\mu-\dfrac{\mu}{\sigma},\dfrac{1}{\sigma^2}\cdot\sigma^{2})\),即 \(Z\sim N(0,1)\),\(Z\) 服从标准正态分布.记 \(\Phi(x)\) 为其CDF.
我们将任意正态分布计算转化为了标准正态分布计算,接下来查表即可.
标准正态分布表

4.4.3 三 σ 法则
若\(X \sim N(\mu, \sigma^2)\),则:
当 \(k = 1, 2, 3\) 时,其值分别为\(0.6826, 0.9544, 0.9974\),即三 \(\sigma\) 法则:几乎所有的值都在平均值正负三个标准差的范围内.
4.4.4 正态分布近似二项分布
当二项分布的 \(p\) 较大时,泊松分布近似不再准确,我们可以使用正态分布来近似.
如图,对于二项分布 \(X\sim \text{Bin}(100, 0.5)\),如果使用正态分布 \(Y\sim N(50,25)\) 近似,其整体近似结果表现十分好.
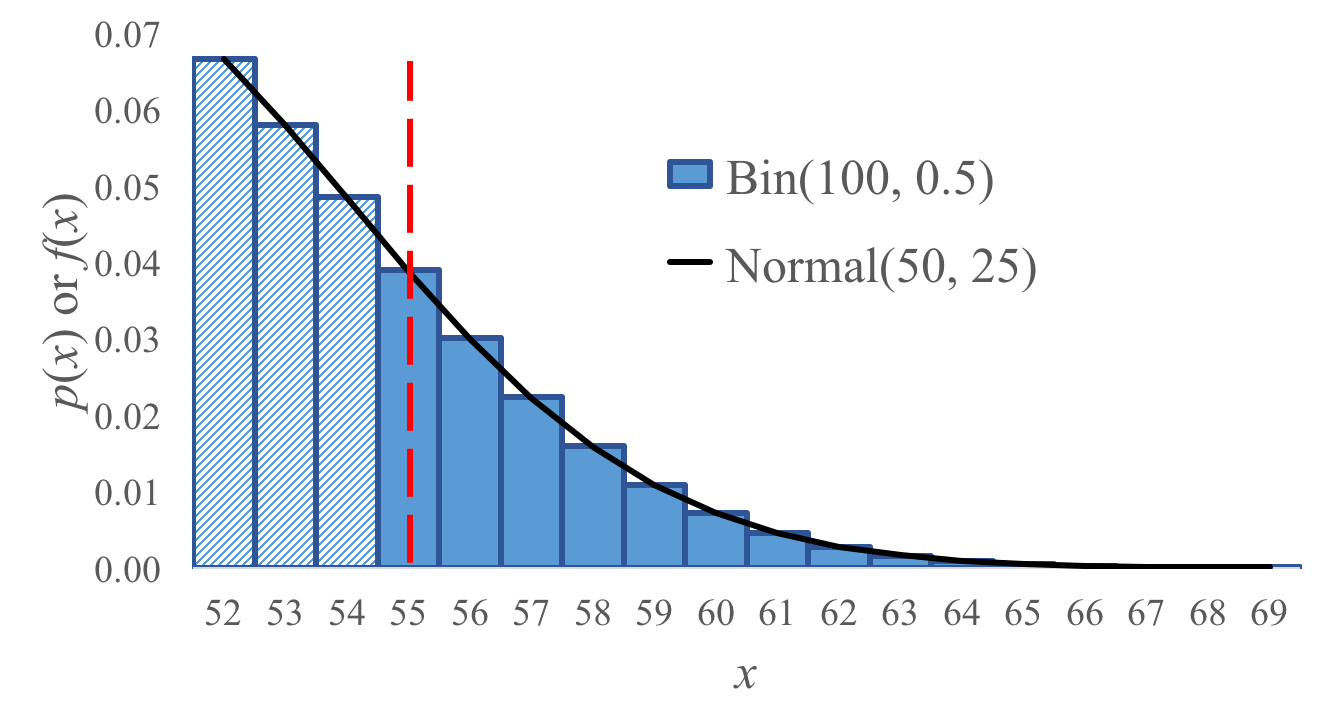
不过需要注意的是,正态分布是连续分布而二项分布是离散分布,我们必须使用连续性校正来离散化正态分布.
当我们想求 \(\text{P}(X\geq 55)\) 时,如果使用 \(\text{P}(Y\geq55)\) 来估计,结果会有一定差距.这是因为我们将连续分布离散化时,实际上 \(55\) 对应的是以 \(55\) 为中心、宽度为 \(1\) 的矩形,即 \(54.5\sim 55.5\).如果使用 \(\text{P}(Y\geq55)\) 来估计,那么 \(X=55\) 的概率实际上只计算了一半;用于补足这缺少的一半,我们应该使用 \(\text{P}(Y\geq54.5)\) 来估计.
| 离散(二项式)概率问题 | 等效的连续概率问题 |
|---|---|
| $\text{P}(X=6)$ | $\text{P}(5.5\leq Y \leq 6.5)$ |
| $\text{P}(X\geq6)$ | $\text{P}(Y\geq 5.5)$ |
| $\text{P}(X>6)$ | $\text{P}(Y\geq 6.5)$ |
| $\text{P}(X<6)$ | $\text{P}(Y\leq 5.5)$ |
| $\text{P}(X\leq6)$ | $\text{P}(Y\leq 6.5)$ |