LLM Architecture
约 175 个字 1 张图片 预计阅读时间 1 分钟
现代大语言模型大多基于 Transformer.GPT、LLaMA 等一类自回归语言模型常用 Decoder-only Transformer 结构.
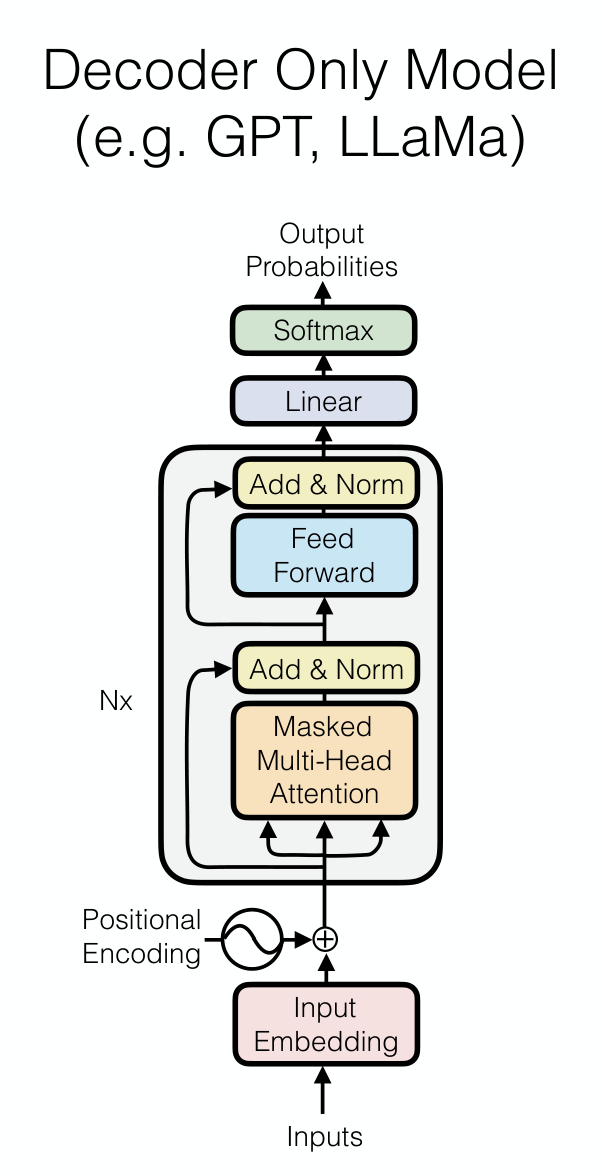
1. Decoder-only Transformer
Decoder-only Transformer 使用 causal mask,使每个位置只能看到它之前的 token,因此天然适合自回归语言建模:
\[
P(X)=\prod_{t=1}^{T}P(x_t|x_1,\dots,x_{t-1})
\]
它通常由多层相同结构堆叠而成,每层包含:
- masked self-attention
- feed-forward network / MLP
- residual connection
- normalization
2. Llama
| Vaswani et al. | Llama | Llama 2 | |
|---|---|---|---|
| Norm Position | Post | Pre | Pre |
| Norm Type | LayerNorm | RMSNorm | RMSNorm |
| Non-linearity | ReLU | SwiGLU | SwiGLU |
| Positional Encoding | Sinusoidal | RoPE | RoPE |
| Attention | Multi-head | Multi-head | Grouped-query |
这张表保留的是架构上的粗略对比.实际模型会因规模和版本而有差异.对于朴素 Llama2 的实现,见 Llama2.